案例分析方法(产品需求分析神器)
任何一个互联网产品,都会涉及到很多的需求,老板、业务提的各种需求时常扎堆,哪怕一个小功能、次次次级页面经常都会争得不可开交。哪个需求对用户来说最重要?用户对我们的新功能是否满意?开发产品资源有限,开发、设计、测试人手总是不够用,这么多需求没办法都做,先做哪些需求?
这些都不应该是拍脑袋想出来的,而应该由产品设计团队的分析师、产品经理,通过客观的分析确定下来。那么如何真正从用户需求出发来梳理出需求层次以及需求优先级,并能进一步判断需求实现对用户影响程度呢?
这时候,就可以引入一个产品需求分析的经典模型「KANO分析模型」,进行系统的需求梳理,对需求进行分析和提炼,提高效率。
KANO 模型是东京理工大学教授狩野纪昭发明的对用户需求分类和优先排序的有用工具,以分析用户需求对用户满意的影响为基础,体现了产品性能和用户满意之间的非线性关系。
1.需求属性分类
通过对需求的满意度、具备度二维分析,KANO将需求划分为必备型、期望型、魅力型、无差异型、反向型五类,分别以英文字母M、O、A、I、R表示。
必备型需求(M):需求满足时,用户不会感到满意。需求不满足时,用户会很不满意。期望型需求(O):需求满足时,用户会感到很满意。需求不满足时,用户会很不满意。魅力型需求(A):该需求超过用户对产品本来的期望,使得用户的满意度急剧上升。即使表现得不完善,用户的满意度也不受影响。无差异型需求(I):需求被满足或未被满足,都不会对用户的满意度造成影响。反向型需求(R):该需求与用户的满意度呈反向相关,满足该要求,反而会使用户的满意度下降。2. better-worse系数
Better系数=(期望数+魅力数)/(期望数+魅力数+必备数+无差异数)
Worse系数= -1*(期望数+必备数)/(期望数+魅力数+必备数+无差异数)
Better系数越接近1,表示该具备度越高该需求对用户满意度提升的影响效果越大。Worse系数越接近-1,表示具备度越低该需求对用户满意度造成的负面影响越大。
KANO分析实战
某公司的A产品将于下个月进行版本更新,产品经理小B收集到了来自各方的产品功能更新需求,为了确定哪些功能确实需要更新,小B决定通过KANO模型进行需求分析。
本次分析实战工具为BI工具FineBI,免费激活码已附在阅读原文,需要自取。
1.调研问卷设计
在做KANO分析前,一般需要进行用户调研。通常采用矩阵量表的形式让用户对功能进行正面和负面评价,评价分为五个程度“我很喜欢”、“它理应如此”、“无所谓”、“勉强接受”、“我很不喜欢”。

调研后对数据进行清洗,本案例清洗后的数据已附在文末,需要的朋友可以进入文末下载。
2.处理数据
(1)在FineBI的自助数据集中,只需要通过编辑字段即可完成数据处理,比如常见的过滤功能、分组汇总功能、新增列、排序功能、合并功能等等;
小B将清洗好的数据上传至 FineBI。添加自助数据集并勾选「KANO原始数据」的所有字段,如下图所示:
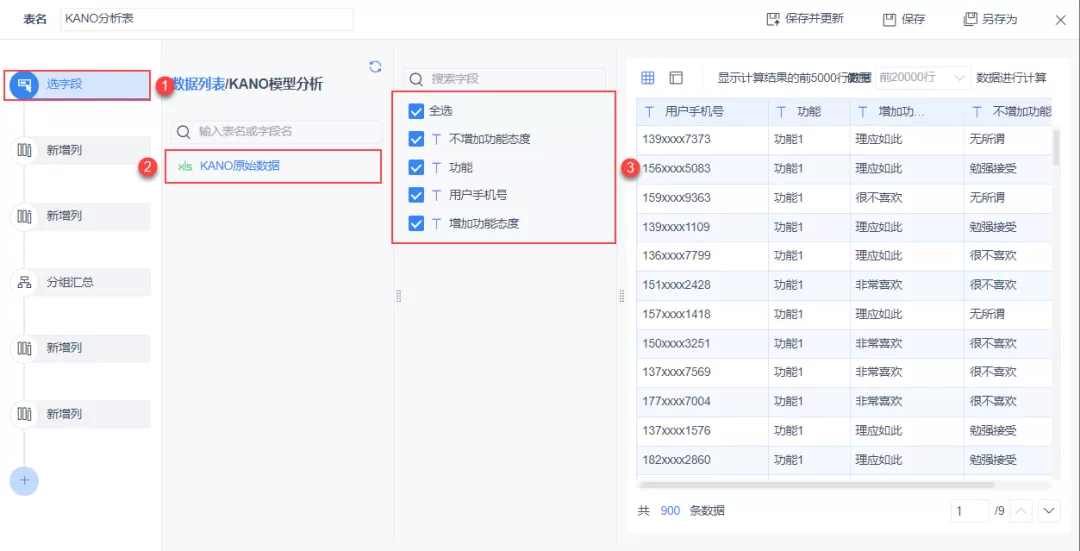
(2)新增列「合并态度」,将「增加功能态度」与「不增加功能态度」进行合并,如下图所示:
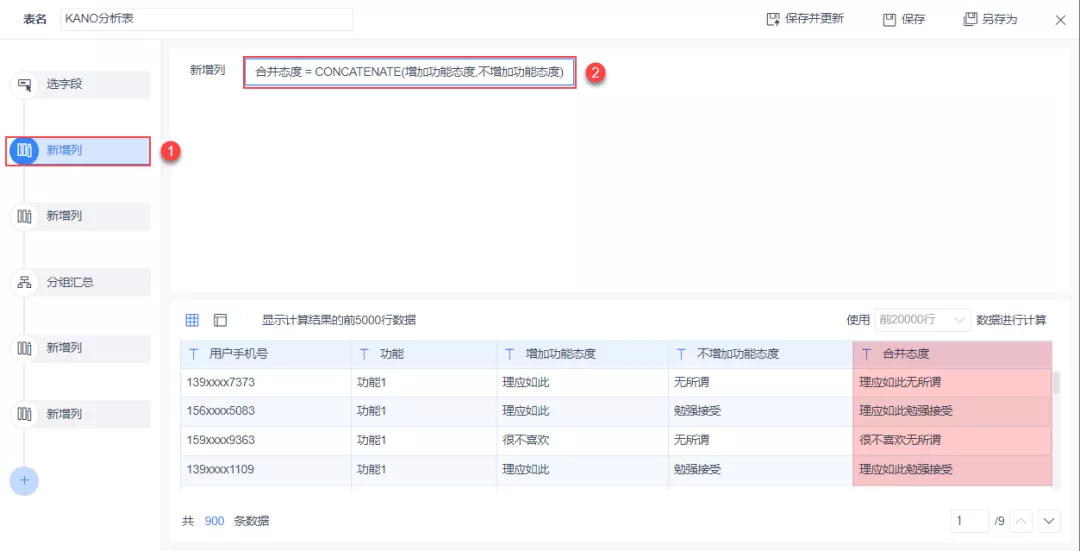
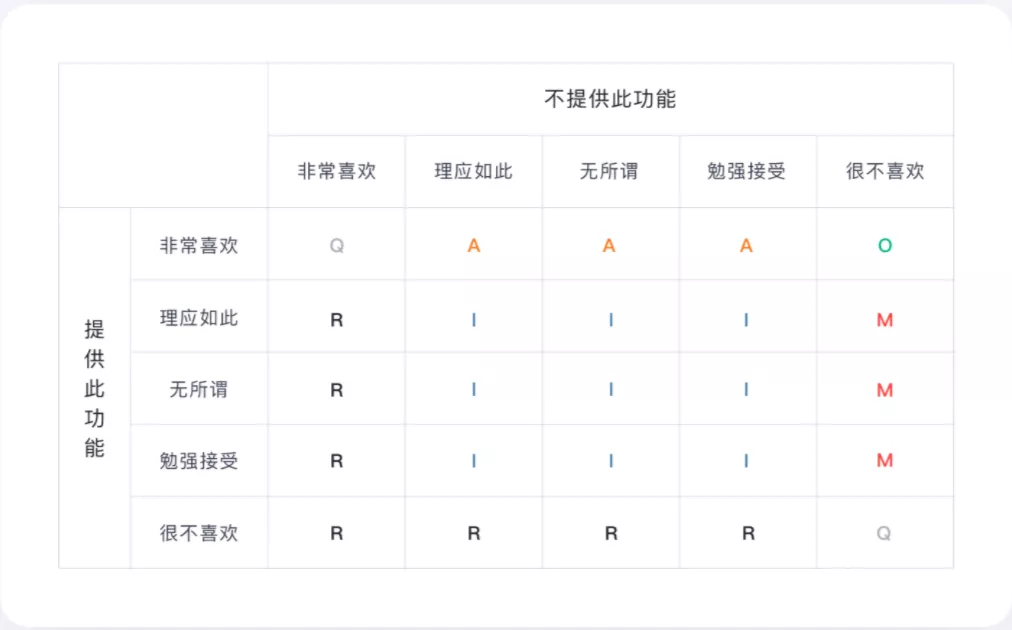
按照用户对「增加功能态度」与「不增加功能态度」,最终我们可以通过下表定位某功能对于用户来说是什么需求。
M:基本(必备)型需求;O:期望(意愿)型需求;A:兴奋(魅力)型需求;I:无差异型需求;R:反向(逆向)型需求;Q:可疑结果
(3)上一步骤我们已经知道如何定位需求类型,接下来要做的就是在分析表中定位判断,添加类型列,此处需使用到switch函数,函数公式如下图所示:
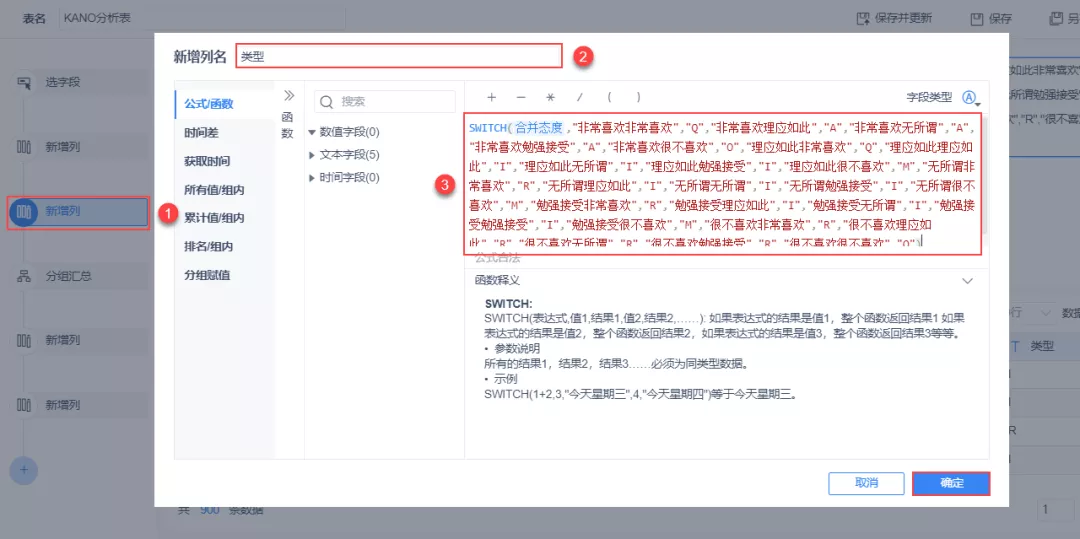
由于公式很长,用户可以直接复制下面到公式列,并用自己的字段替代「合并态度」:
效果如下图所示:
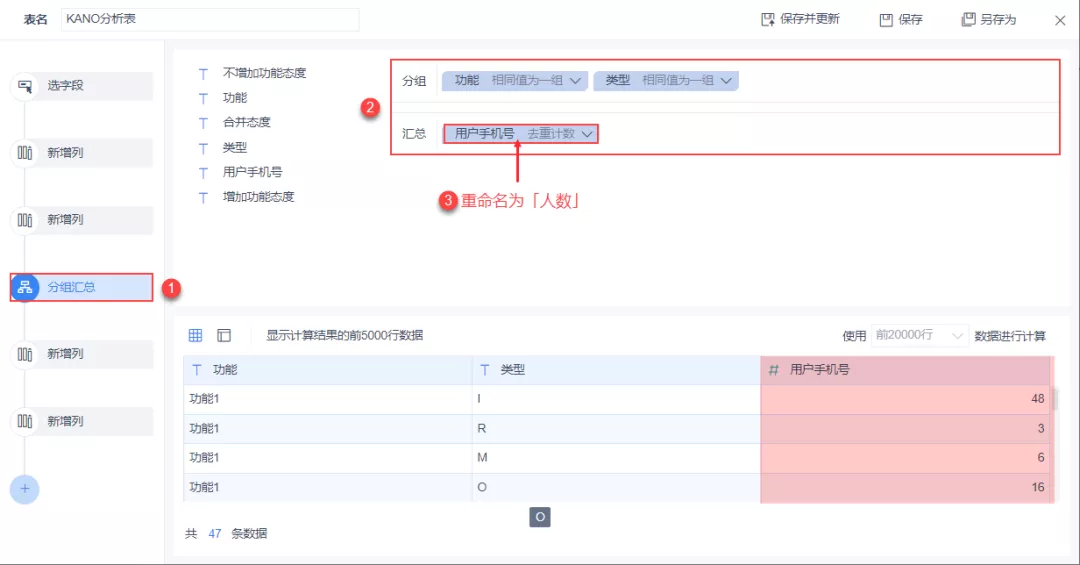
(4)添加「分组汇总」,得到每个功能它们各种需求类型的人数,如下图所示:
例如参与调研的人数中,认为「功能1」是无差异需求的人数有 48 人。
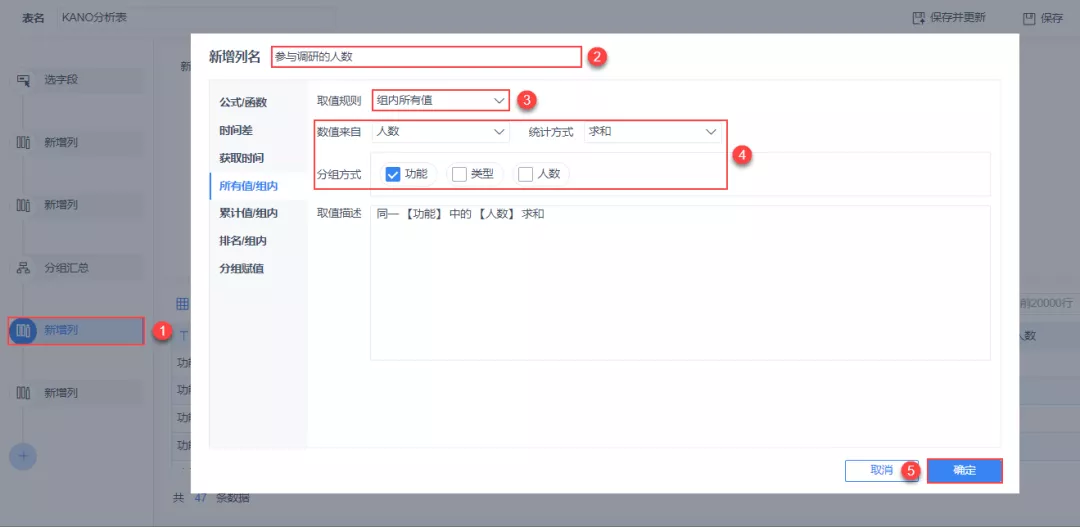
(5)因为调研过程中有些用户会跳题,所以参与每个功能调研的人数有所不同。新增列「参与调研人数」,选择「组内所有值」,如下图所示,求出参与每个功能调研的人数。
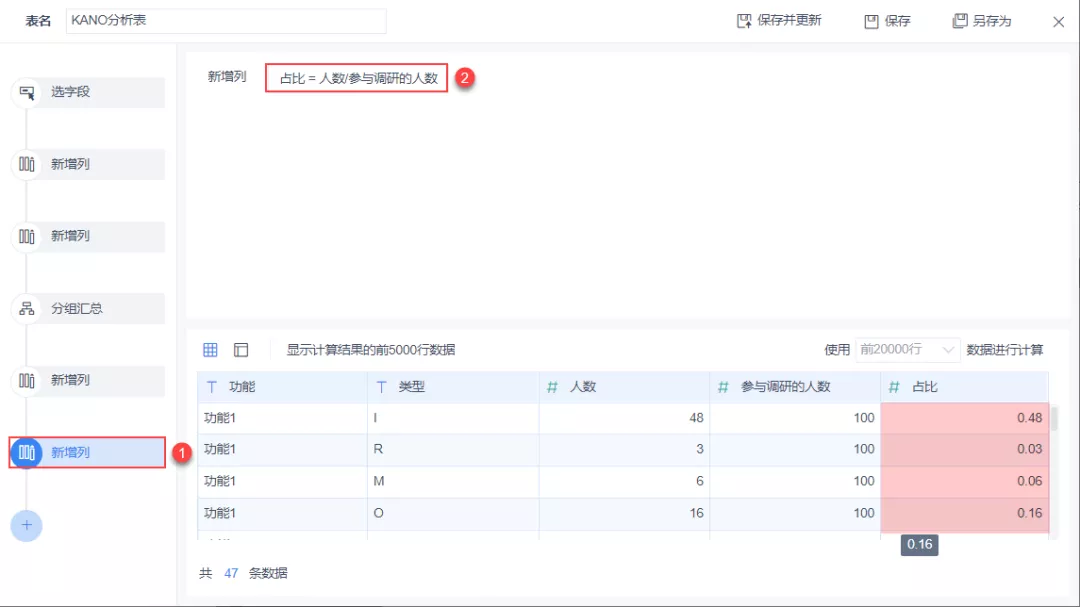
(6)计算占比,求得每个需求类型占参与调研人数的比例。
例如「功能1」的 「I 类型人数」占参与「功能1」调研人数的占比为 0.48。如下图所示:
3.分析结果可视化
通过FineBI的仪表板,可以将数据进行可视化组件呈现,其中内置了几十种分析图表,可以满足绝大部分的可视化分析需求。小B进入仪表板中,新建组件选择刚刚处理过的自助数据集。
(1)复制 5 个「占比」字段,如下图所示:
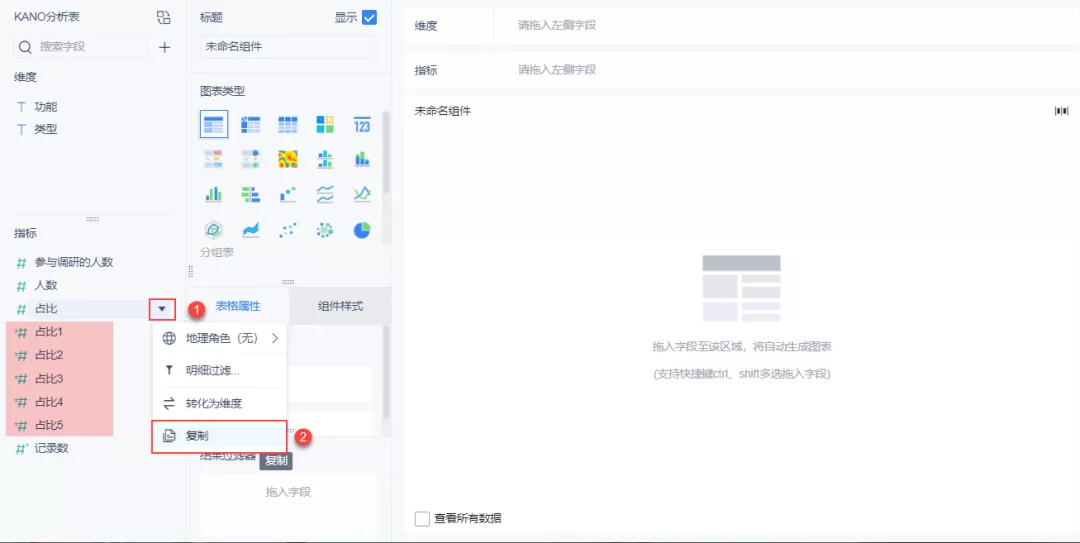
(2)对复制的「占比」字段进行明细过滤,过滤条件为:类型属于 A 。并将其重命名为「A 占比」。如下图所示:
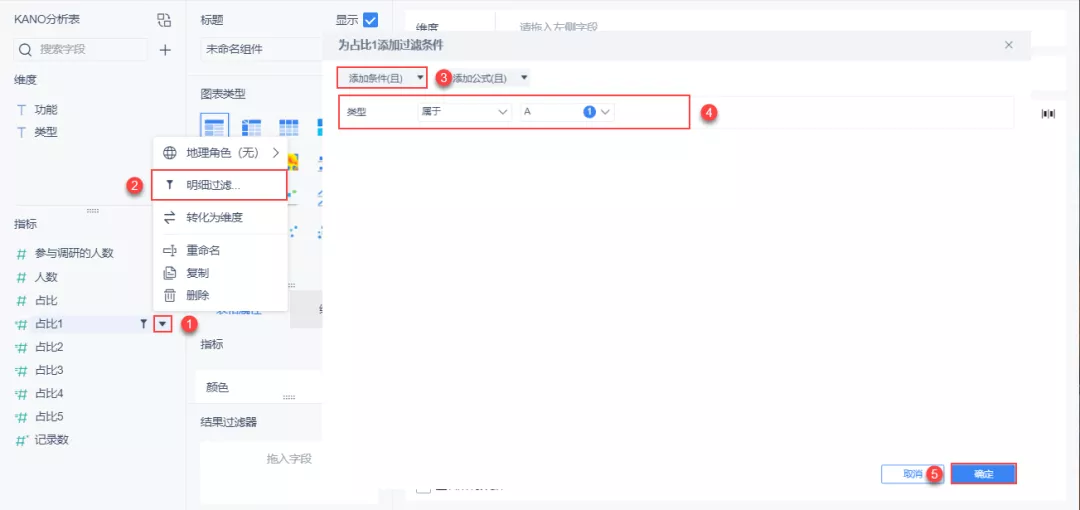
同理对其他复制的「占比」字段进行明细过滤,分别过滤类型,并对其重命名,如下图所示:
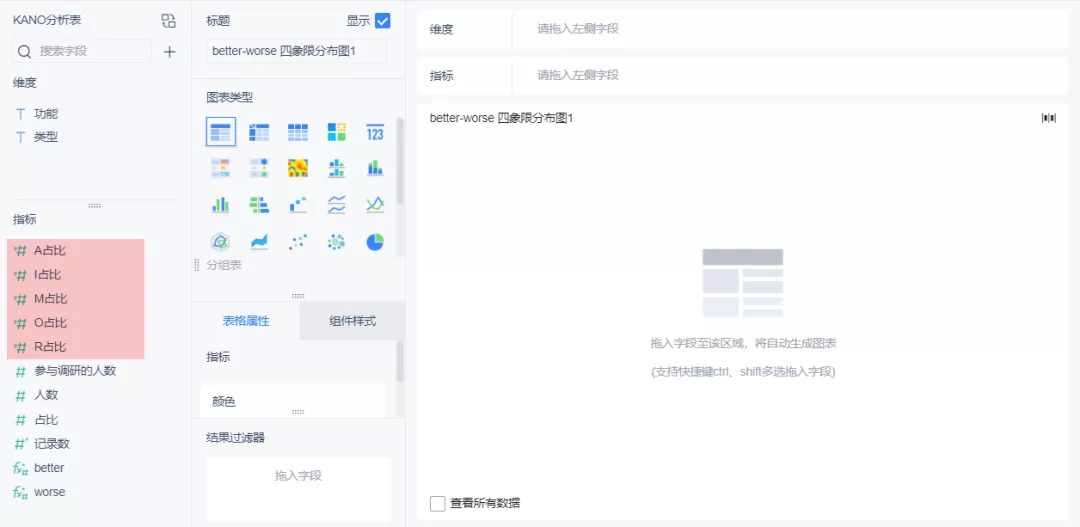
(3)使用 better-worse 系数,如下图所示:
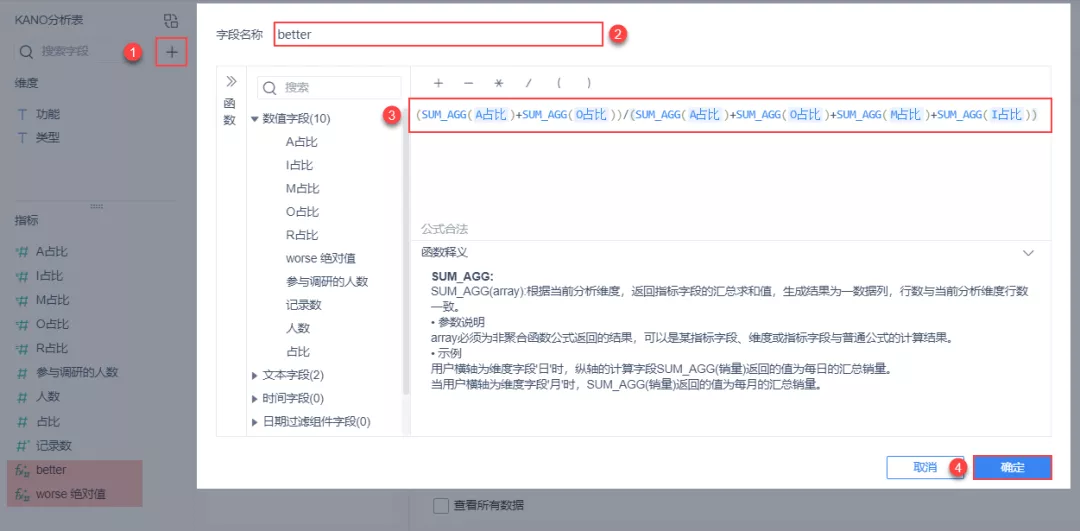
better-增加某功能后提升的满意系数:better=(A占比+O占比)/(A占比+O占比+M占比+I占比),越接近 1,则表示用户满意度提升的效果会越强,满意度上升的越快。worse-不增加某功能用户的不满意系数:worse=-1*(O占比+M占比)/(A占比+O占比+M占比+I占比),越接近 -1,则表示对用户不满意度的影响最大,满意度降低的影响效果越强,下降的越快。根据以上灰字中的better、worse 的公式,新建计算字段「better」「worse绝对值」,如下图所示:
(4)选择「散点图」,拖入「better」、「worse绝对值」字段。并将「功能」字段拖入图形属性的标签栏和颜色栏。如下图所示:
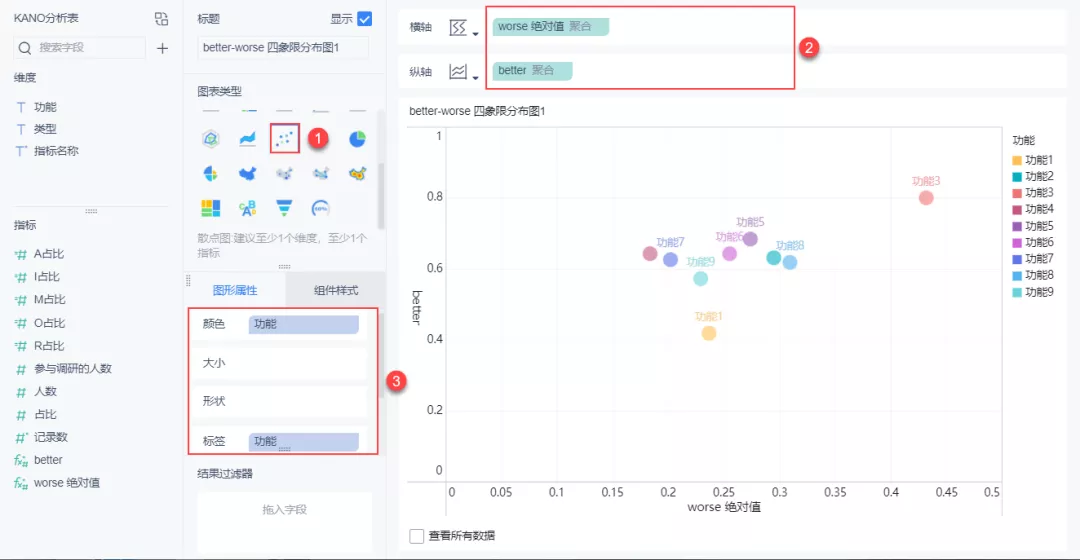
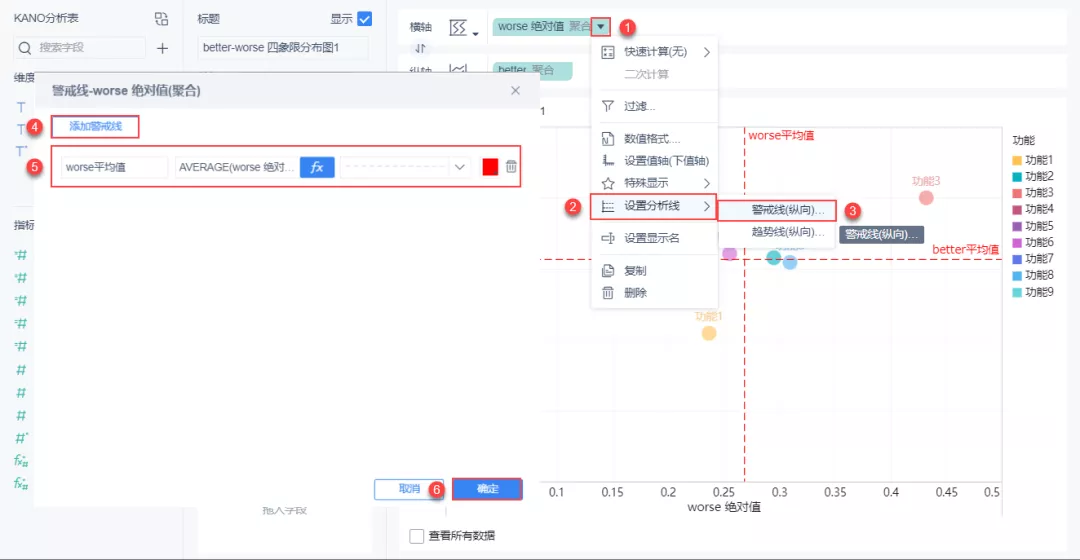
(5)分别添加「横向警戒线」和「纵向警戒线」,分别为 better平均值 和 worse平均值 。如下图所示:
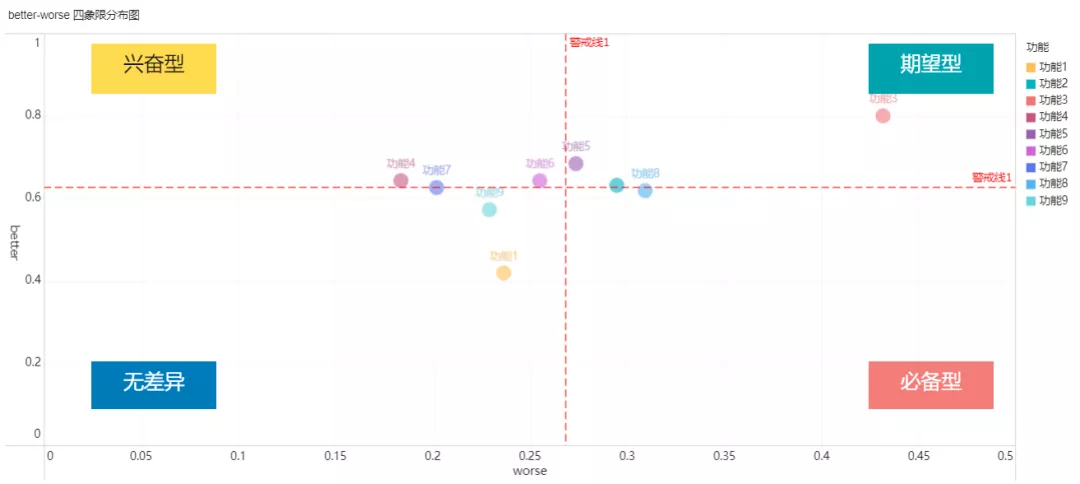
4.分析结果展示
最终,小B做出了如下better-worse四象限分布图,并将将做好的仪表板分享给了同事,决定此次功能更新增加「功能2、功能3、功能5、功能8」。有了数据支撑,大家都很认同他的决定,罕见地没有出现以往为增加哪个功能而争得不可开交的局面,提升了效率。
以上就是KANO分析的全部过程,在实际工作场景中,情况更加多变,因此需理解此模型分析逻辑,灵活变通。
文末惊喜
本文数据已打包好,回个“KANO”就能获得工具!
声明:本文由"麦兜"发布,不代表"知识分享"立场,转载联系作者并注明出处:https://www.wuxiaoyun.com/law/16341.html
