免费英语句子分析器(希伯来大学)
ACL 2018 Long Papers
使用语义和神经网络方法进行简单有效的文本简化
Simple and Effective Text Simplification Using Semantic and Neural Method
耶路撒冷希伯来大学
The Hebrew University of Jerusalem
本文是耶路撒冷希伯来大学发表于 ACL 2018 的工作,本文提出了一种简单有效的基于自动语义解析的分割算法。分割之后,文本可以进行进一步的微调简化操作,在这种情况下可以有效地使用神经机器翻译。机器翻译在简化任务上的早期应用存在一个不可忽视的缺点,那就是过于保守,经常不能以任何方式修改源代码。本文提出的基于语义解析的拆分方法有效避免了这个问题。实验表明该方法在词法和结构简化的组合方面都优于目前的最好方法。

1 引言
文本简化(TS)一般被定义为将一个句子转换成一个或多个简单的句子。在诸如机器翻译和关系提取,以及阅读辅助工具开发(例如,对于有阅读障碍的人或非母语者)的预处理步骤等任务中,都已被证明是非常有用的。TS包括结构化和词汇化运算。核心的结构简化操作是句子切分,即将一个句子重写成多个句子,同时保留其原始含义。虽然最近使用神经MT(NMT)方法已经取得了巨大进展,但是这些系统并没有解决句子切分的问题,主要是由于训练语料库中这种情况比较的罕见。
我们发现在简化系统中显式地集成句子切分可以缓解基于NMT的TS系统的保守性,它严重影响了模型效能。的确,用最先进的神经系统进行实验,我们发现66%的输入句子保持不变,而没有相应的引用与源相同。通过人工和自动评估,确认参考文献确实比源文献简单,这也表明观察到的保守性是过度的。本文方法使用句子分割进行预处理,允许TS系统执行其他操作(例如,删除)和词汇(例如,单词替换)操作,从而提升了结构和词汇的简化性。
本文首次将结构语义学与神经网络方法相结合,提出了基于语义解析的直接语义切分(DSS)算法,它是一种简单、高效的基于语义解析的算法,支持将句子分解为多个核心语义成分。分割之后,使用NTS系统执行基于NMT的简化。实验表明本文方法优于现有领先方法。本文使用UCCA方法进行语义表示,进一步利用UCCA中场景(事件)类型的明确区别,为每个场景应用特定规则。
2 模型
语义表示UCCA是一种植根于类型学和认知语言学理论的语义标注方案。它旨在展示文本中的主要语义现象,从句法形式中抽象出来。在翻译任务中,已经证明了UCCA在语义保存上做得非常好,并且已经被成功地用于机器翻译的评估,并且最近成功地应用于TS评估和语法纠错。
场景是UCCA关于事件或框架的概念,指的是一些持续存在的运动、动作或状态单元。每一个场景都包含一个主要的关系,它可以是一个过程,也可以是一个状态。场景包含一个或多个参与者,广义上包括位置和目的地。例如,句子“He went to school”只有一个场景,其过程是“went”。两个参与者是“He”和“to school”。
场景可以在文本中有多个角色。首先,它们可以提供关于已建立的实体(精细化场景)的附加信息,通常是分词或关系子句。例如,“(child) who went to school”是“The child who went to school is John”中的精细化场景(“孩子”既是精细化场景中的论点,也是中心)。场景也可以是另一场景中的参与者。例如,句子“He said John went to school” 中的“John went to school”。在其它情况下,场景被标注为平行场景(H),它是扁平结构,可以包括连接器(L),如:“WhenL [he arrives]H , [he will call them]H”。
对于那些不是场景的单元,类别中心表示语义头部。例如,“dogs”是“big brown dogs”的表达中心,“box”是“in the box”的中心。在一个单元中可能有一个以上的中心,例如在coordination的情况下,所有的结点都是中心。我们将UCCA单元u的最小中心定义为UCCA图的叶子,从u开始,迭代地选择标记为中心的子节点。
为了生成UCCA结构,本文使用一个基于转换的解析器TUPA(具体地,TUPABiLSTM模型)。TUPA使用一组变换表达组合,能够支持UCCA方案所要求的结构特性。给定词嵌入和其他特征,其变换分类器是基于接收解析器状态(缓冲区、堆栈和中间图)元素BiLSTM编码的MLP。
语义规则为了执行DSS,我们在UCA范畴的条件下定义了两个简单的切分规则。目前我们只考虑平行场景和精细化场景,不分离参与场景,以避免在名词化或间接讲话的情况下切分。例如,句子“His arrival surprised everyone”,除了“surprised”引发的场景之外,“arrival”引发的参与场景在这里没有切分。
规则#1:提取给定语句的并行场景,分隔成不同的语句,并根据出现顺序进行连接。给定将句子S分解为并行场景
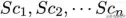
(按第一个token的顺序索引),我们得到以下规则,其中“|”是句子分隔符:
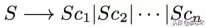
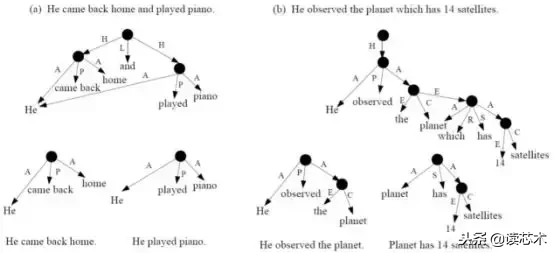
由于UCCA允许场景之间的参数共享,所以规则可以在语句之间复制相同子跨度S。例如,这个规则会把“He came back home and played piano”变成“He came back home”|“He played piano.”。
规则#2:给定一个句子S,第二条规则提取精细化场景和相应的最小中心。然后将精细化场景连接到原始语句,其中除阐述最小中心的精细化场景外,其他的都被删除。代词如“who”、“which”和“that”也被删除。
形式上,如果

是S及其对应的最小中心的精细化场景,重写为:
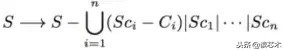
其中S-A指的是没有单元A的S。例如,这条规则将“He observed the planet which has 14 known satellites”的句子转换为“He observed the planet| Planet has 14 known satellites.”。文章重组不被规则覆盖,因为它的输出被直接送到NMT组件中。
在提取并行场景和精细化场景之后,将得到的简化并行场景放置在精细化场景之前。请参阅图1。
句子切分是通过NTS状态的最先进的神经TS系统,使用OpenNMT神经机器翻译框架构建的。该体系结构包括两个LSTM层,每个隐藏状态包含500个单元,以及与输入相结合的全局注意力机制。训练以0.3的dropout概率完成。该模型使用预测句与原句之间的对齐概率,而不是基于字符模型来检索原始单词。
本文考虑W2V初始化NTS(N17),其中word2vec词向量的大小为300,使用谷歌新闻进行训练,本地词向量大小设置为20,在简化语料上进行训练。编码器的局部词嵌入在训练语料库的源端进行训练,而解码器的局部词嵌入在简化端进行训练。
为了采样来自系统的多个输出,解码期间,在给定输入句子的目标句子进行对数似然度排序,通过每个步骤生成前5个假设来执行集束搜索。我们在此探索最高(h1)和第四级(h4)假设,这说明增加了SARI评分,而且不那么保守。因此我们用NTS-h1和NTS-h4表示的神经成分的两个变体进行实验。规则和神经系统的两个相应的模型:SENTS-h1和SENTS-h4。
3 实验
语料库:所有系统的测试语料库来自2016年的Optimizing statistical machine translation for text simplification论文中提出的语料集,包括359个从PWKP语料库中,通过众包收集的8篇参考文献。
语义部分:TUPA 解析器是在UCCA标注的Wiki语料库上进行训练的。
神经成分:使用N17提供的NTS-w2v模型。训练集基于标准英语维基百科和简单英语维基百科之间的手动和自动对齐,它们的相似性分数高于0.45。训练集的总大小约为280K个对齐句子,其中150K个句子为完全匹配,130K个句子为部分匹配。
启发式问题在下表中给出。

根据前人工作研究,语法(G)和意义保存(M)使用1到5的尺度来测量。请注意,在第一个问题中,没有考虑输入语句。通过评估Identity转换(参见下表)来评估输入的语法性,从而为其他系统的语法性分数提供基线。
结果如下表所示。Identity获得比任何其他系统高得多的BLEU得分,这表明BLEU可能不适用这个设置。SARI似乎更具信息量,并将最低分数分配给identity,次高分配给reference。
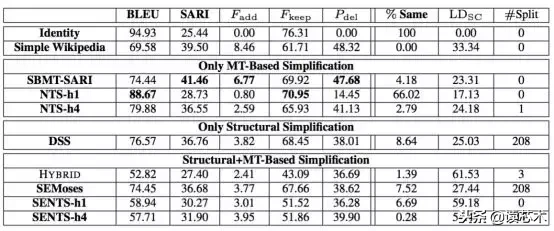
Moses的不同组合与DSS的评价结果如下。

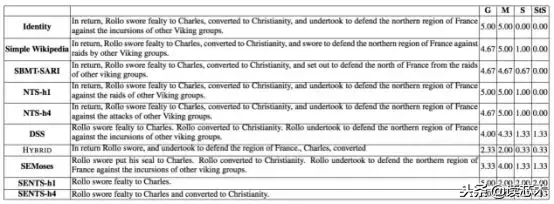
系统输出的一个测试句子与相应的人类评估分数(平均3个标注者)。
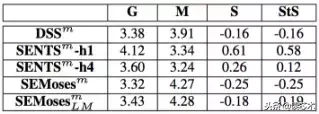
人工评价使用人工UCCA标注,语法(G)含义保存(M)使用1到5的规模量化。输出句子的简洁性(S)和结构性(StS)使用-2到+2规模进行量化。Xm指的是系统X的半自动版本。
4 总结
本文提出了一种语义结构和神经机器翻译相结合的简化系统,实验表明它优于现有的词法和结构系统。所提出的方法解决了基于MT的TS系统过于保守的问题,TS系统通常不能以任何方式修改源。语义组件进行句子切分可以不依赖于专门的语料库,而仅依赖于现成的语义分析器。考虑将句子切分看作把句子分解为多个场景,进一步将SAMSA度量假设应用于不同目的(TS体系结构和TS评价),验证了其有效性。未来的工作将利用UCCA的跨语言适用性来支持MT\的多语言TS和TS预处理。
论文下载链接:
http://aclweb.org/anthology/P18-1016
声明:本文由"麦兜"发布,不代表"知识分享"立场,转载联系作者并注明出处:https://www.wuxiaoyun.com/zhishi/11328.html
